In November 2015 John Mueller announced that Googlebot would soon be able to request URLs over the HTTP/2 protocol. This currently isn’t possible, but with Google’s aim of improving its search offering and particular focus on mobile search, accommodating HTTP/2 must be on their To Do List for 2016.
What is HTTP/2?
HTTP is the foundation of the internet and the transferring of data from client to server (and vice-versa). So when you enter a URL in your browser, the browser sends the request to the web server via HTTP, and the server delivers the information through the same method. It sort of acts like the delivery van for information across the internet.
HTTP/2 is the modernised version of HTTP. Whereas HTTP was developed to handle the small websites and low traffic levels around the time of its inception (last modified in 1999!), the internet has developed massively since then and therefore needs a new method of handling all these requests for information.
How does it work?
The main difference between HTTP and HTTP/2 is how they handle requests and responses. HTTP will only allow one request per connection to the server at any one time, and therefore as the number of requests adds up, you can see how loading a webpage will start to take longer and longer.
![]()
It’s like placing an order at an online shop, and waiting for one item to be delivered before ordering the next one.
This is best visualised when analysing the load speed performance of a webpage through WebPageTest.org:
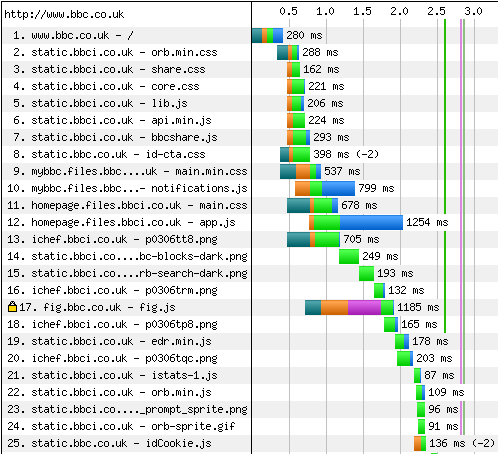
Figure 1 – Test results from www.webpagetest.org
The green section of each bar indicates the time spent waiting for the first byte of data to be received. This waiting time is typically much longer than the time taken to actually receive the entire resource!
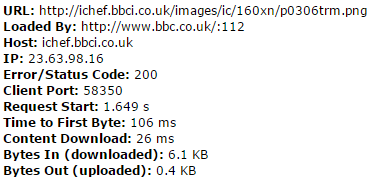
Figure 2 – Test results from www.webpagetest.org
As you can see above, the Time to First Byte for this resource was 106ms but only took a further 26ms to fully download. Also, the waterfall image shows resources loading one after another, meaning that the total length of time taken for the page to download increases with each new element on it.
This is something that HTTP/2 will address. Instead of requesting and receiving each resource one at a time (or in small batches), HTTP/2 will operate in such a way that information can be simultaneously requested and received, looking something like this:
![]()
To go back to our analogy, we’re now placing an order for all our items at once, and they’re all being delivered at once. A much more efficient system and – crucially – much faster.
So what does all this mean?
There’s a number of key implications that result from utilising HTTP/2. Firstly, massively reduced ‘down time’. Because requests are being sent and received in tandem with one another, there’s no such thing as downtime because there’s always something that the server or browser could be doing to load the page.
Another issue that inhibits a lot of sites currently is the number of resources that block any other activity until they have finished downloading. For example, if you have a 2mb image at the top of your page, this could take ages to download and nothing else will get going until it’s done. This becomes a thing of the past with HTTP/2.
HTTP/2 will also deliver resources to the browser before they’ve even been requested – that will be resources that the server knows are going to be requested as part of the page load. Think about elements such as your logo, JavaScript files or social media profile images. These will appear on every page and HTTP/2 can send them to the browser without having to wait for them to be requested. More time saved!
What’s the benefit for SEO?
The biggest benefit for SEOs is load speed. Google has made it quite clear that speed is a factor in its ranking algorithm and with the recent rapid growth of mobile search, this is bound to be a more influential factor than it was back in 2010 (the date of the official announcement). It has developed its own PageSpeed Insights tool and Google Analytics site speed report to give webmasters the information they need to improve load time performance. If webmasters can make their content load quickly (and therefore encourage users to remain on the page) then they will start to reap the rewards in terms of organic rankings.
This leads onto another element of SEO that is more and more coming to the forefront of people’s minds, and that is user experience. Providing content that loads quickly and (hopefully) satisfies the users query will go a long way to reducing bounce rate and bounce-back-to-SERP rate, both of which will be valued by Google and built into the ranking algorithm.
So we should all switch to HTTP/2, right?
Well, no. Not yet anyway. Google is still developing Googlebot to be able to crawl URLs over the HTTP/2 protocol and even though switching in the meantime wouldn’t result in Google being unable to crawl your content (it would simply access it through ‘regular’ HTTP), you could see a number of losses if you do switch too soon. Any stop-gap measures you’ve put in place on your current site such as compression, minification or asynchronous loading of resources might be reversed with the implementation of HTTP/2 support and that would certainly have an impact on how Google perceives your site and its load speed.


