


![]() Insights
Insights
Technical SEO Consultant
Technical SEO
JavaScript technology has been around for many years, and more and more websites are adopting it in some form – entire websites can be, and are being, built from scratch using JavaScript. However, the use of JavaScript causes an issue with most search engines as they are unable to analyze the content, and therefore index it. Because of this, JavaScript and SEO has become an increasingly hot topic in the industry.
In this blog, we will cover six rules to live by to overcome mistakes which are commonly made by companies using JavaScript.
For technical SEOs, this rule comes as no surprise – yet we still see this mistake being made on websites today.
Historically, many CMS had .js or .css files – which are essential to render template content – buried deep within the admin directories. For security reasons, these directories would be blocked using robots.txt – search engines were unable to crawl JavaScript or CSS at the time, so blocking the robots didn’t affect website performance.
This changed in 2014 when Google announced that they would now be able to crawl such resource files and it is important that you don’t block GoogleBots from accessing them. With Google updating their crawling and indexing system from an old text-only browser to a modern page rendering browser, blocking JavaScript can negatively impact your SEO.
Now that Google can crawl and render JavaScript content, blocking the content means search engines are no longer able to index that part of the page. If the JavaScript forms a big part of the page, there are chances that the page will not be indexed at all.
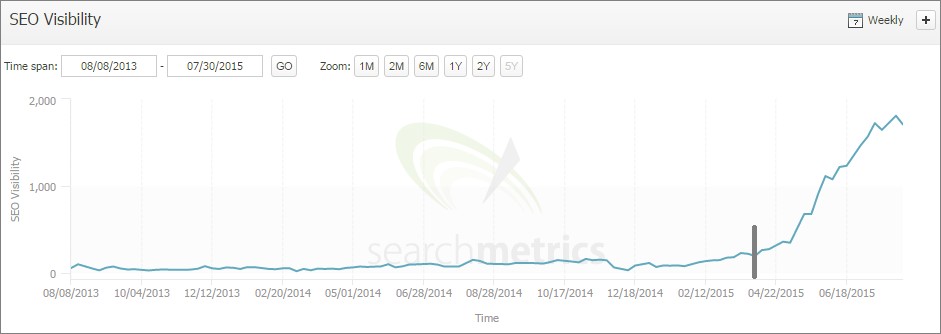
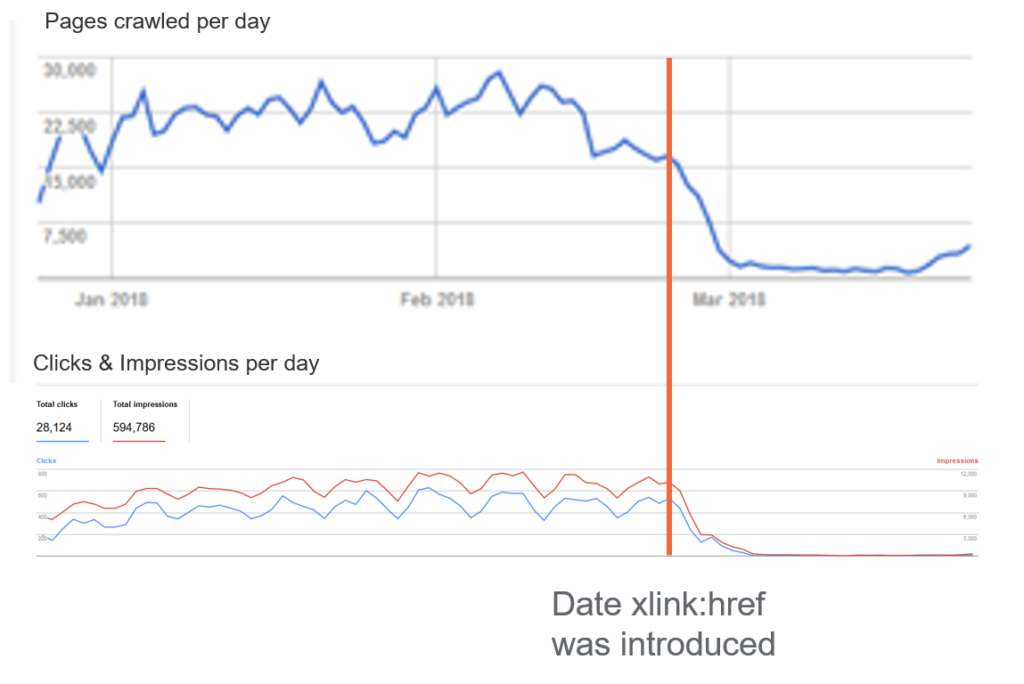
If this is a persistent sitewide issue, you might receive a message in your Google Search Console: ‘Googlebot cannot access CSS and JS files’. We have covered this issue in a previous article and we strongly recommend that you unblock access. As previously demonstrated, this simple action can dramatically change your SEO rankings:
If you haven’t received a message in Google Search Console but believe your site may have blocked JavaScript, using the Google Mobile Friendly Test is one of the best ways to find out if the JavaScript files are blocked by robots.txt.
The test works on a page by page principle however these issues are generally site-wide so checking main templated pages (category landing page, product landing page, blog post, etc.) will usually highlight if there is a site-wide issue.
First, enter a URL and wait for the test result:
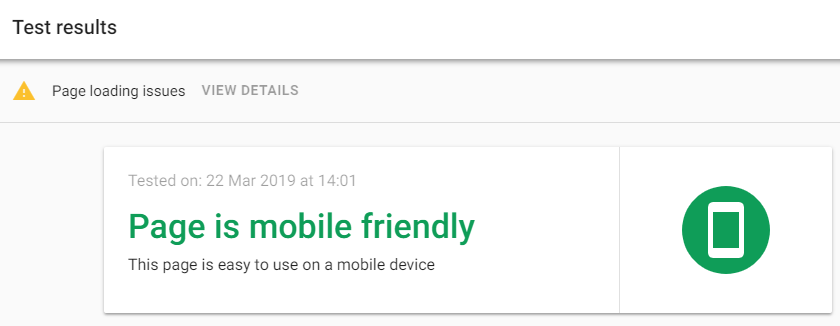
Second: if you see “Page Loading Issues”, click on “View Details” and a new page will open:
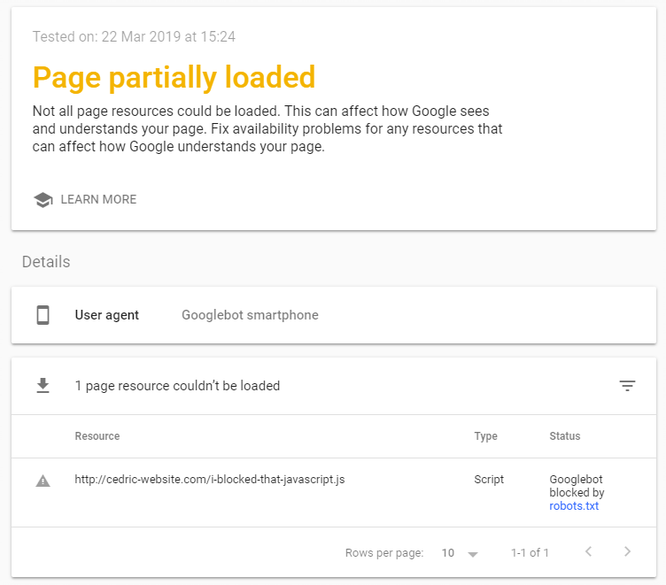
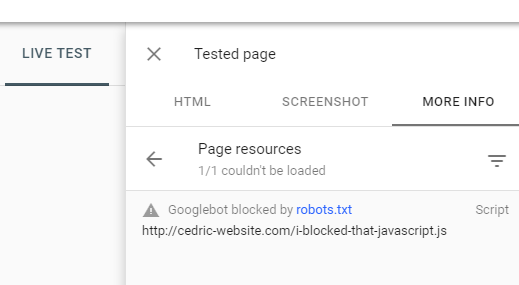
In this example, there is one page resource that couldn’t be loaded – the status is ‘GoogleBot Blocked by robots.txt’. The culprit (in bold) specifies that all files with extension .js (JavaScript) need to be blocked from crawling.:
User-agent: *
Disallow:
Disallow: /*.js$
This has now replaced the Fetch and Render tool which has been deprecated in the old Search Console, and runs on the same principle as the Mobile Friendly Test.
When you inspect a URL from the same domain as the verified property, you will get this:
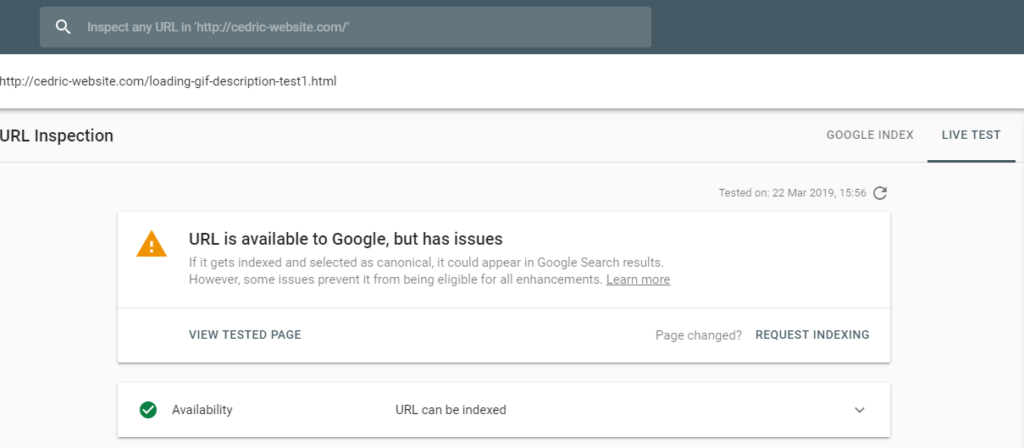
To find out if there are any blocked resources, run a Live Test. If there are any blocked resources, you will see the below message in Page resources under the More info tab in the right-hand corner.
There are two levels of actions, depending on whether you host your domain or not. If you host your own domain, resolving the issue simply involves identifying the robots.txt rules which are causing the issue and amending them to allow crawling and rendering of the resources.
It’s little trickier if you do not host your own domain, as it is likely to be a third-party tool which has blocked access to GoogleBots in their own robots.txt. While some of these tools may not affect content rendering, others will. In these cases, it’s important to contact the third-party tool and get them to unblock their robots.txt for .js and .css files.
Again, this is a rule most technical SEOs will be familiar with, as it is directly related to performance and page loading speed. When placed at the top of a web page, JavaScripts slow down the rendering process for both users and crawlers – this is known as render blocking.
First mentioned on the PageSpeed Insights tool, the industry has learnt a lot about how Google renders pages:
Having good Page Speed is a crucial aspect of SEO; content needs to be loaded by the five second threshold for the web page to be indexed by Google.
Websites containing a lot of JavaScript require more processing power from both website servers and GoogleBot crawlers. JavaScripts are loaded in order of appearance; this means that when they are placed at the top of a page, JavaScripts slow down the rendering process. This can prevent the website loading in the five second threshold and prevent the page from being indexed.
As of November 2018, PageSpeed Insights fully integrates with LightHouse Performance Audit, which can identify when there is an issue with render blocking JavaScript.
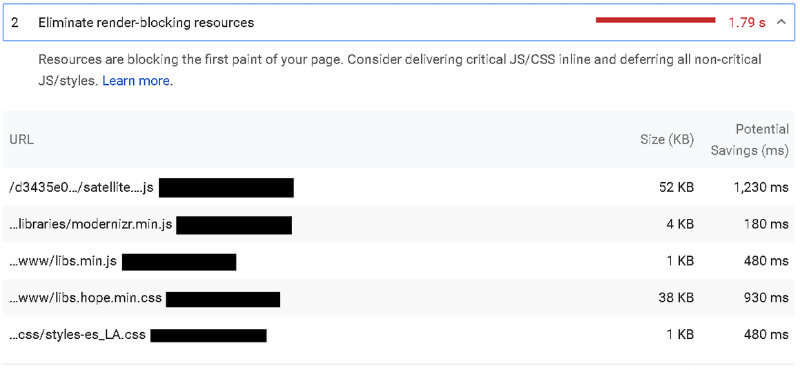
Running a LightHouse audit will highlight all render blocking scripts; you will then need to identify which are ‘critical’ and ‘non-critical’ JavaScripts. While critical scripts are crucial to the page’s core functionality, non-critical scripts are not necessary for the page to load and can be removed from the critical rendering path to ensure that GoogleBot parses the web page, without waiting for the JavaScript content to load first. This can be done using the async attribute.
Small critical scripts can be inserted directly into the HTML document (known as inlining): this unblocks rendering while ensuring that style is applied to the above-the-fold content straight away.
As mentioned above, inlining script is recommended for small critical JavaScripts. However, it is bad practice to inline large amounts of JavaScript; parsing is carried out in the order of appearance so large JavaScripts in the <head> means the page takes longer to crawl. As we know, any page that takes longer than five seconds may not be indexed by GoogleBot.
The biggest issue we come across in this scenario is when attributes such as <link rel=”canonical”> or <link rel=”alternate” hreflang> or <meta name=”robots” content=”index,follow”> find themselves buried under large inlined JavaScript.
The best simple way is by using the “view page source” in a web browser and check if there are any large <script> inlined in the <head> above important attributes for SEO:
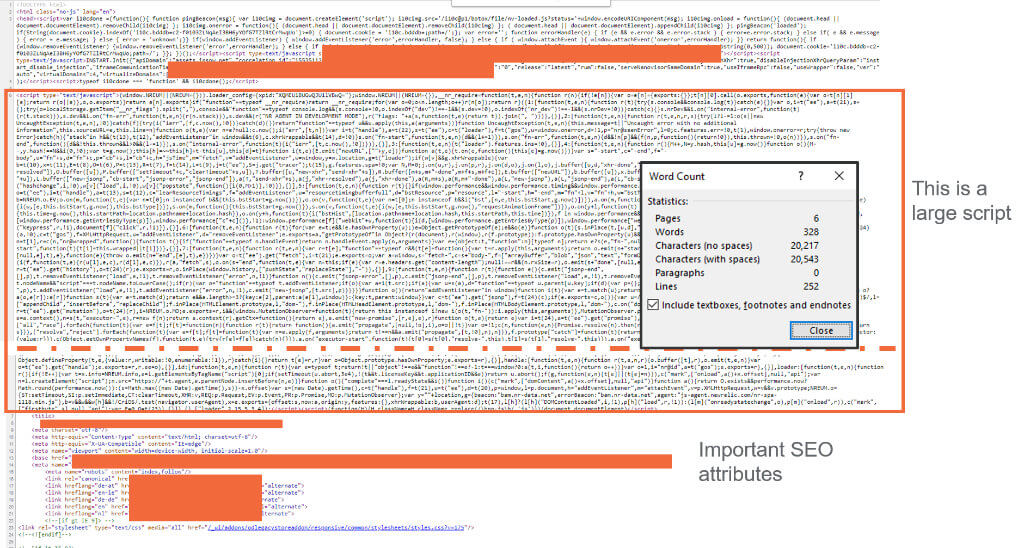
Large scripts like this take a long time to load, and when combined with other external render blocking scripts located in the <head>, make it likely that important SEO attributes are not rendered.
It is recommended to place your important SEO attributes as close as possible to the beginning of the <head>. This is especially true for the following:
When it comes to using <link rel=”alternate” hreflang>, Google recommends the following as best practice:
Put your <link> tags near the top of the <head> element. At minimum, the <link> tags must be inside a well-formed <head> section, or before any items that might cause the <head> to be closed prematurely, such as <p> or a tracking pixel. If in doubt, paste code from your rendered page into a HTML validator to ensure that the links are inside the <head> element.
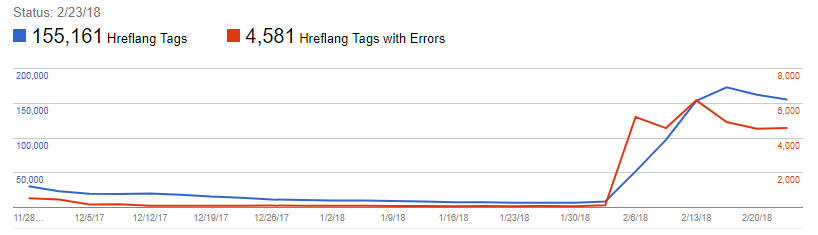
If you’ve found a lot of script in the <head> and moved your hreflang attributes above them and near the top of the <head>, the best way to visualize success when doing so is by checking the “International Targeting” report in Google Search Console. A sudden rush of detected hreflang tags should appear in your report:
W3C describes the DOM as: The Document Object Model is a platform- and language-neutral interface that will allow programs and scripts to dynamically access and update the content, structure and style of documents. The document can be further processed, and the results of that processing can be incorporated back into the presented page.
DOMs which are processed, and then incorporated back into the presented page can negatively impact your website’s SEO. It is difficult to immediately detect any down lift, as Google does not crawl the JavaScript immediately – it takes a lot of time for Google to render all JavaScript content on a page. The process is as follows:
With some websites taking weeks for the second crawl to occur, they may suffer from consequences of reduced online visibility long before the problem is identified.
The first step to detect if this is an issue is to disable JavaScript in the browser. This is an easy way to see if content has been changed or added on page using JavaScript, as the page will look differently depending on if JavaScript is enabled or disabled.
This example shows what a page looks like when JavaScript is enabled (left) versus disabled (right).
Javascript is enabled

Javascript is disabled
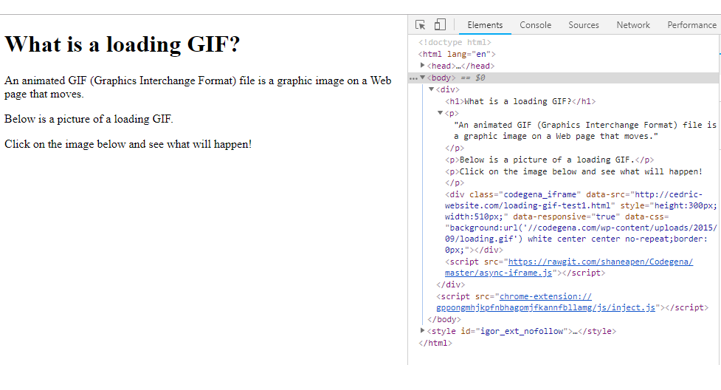
In this example, a <H1> has been injected with JavaScript and will only appear when the DOM is loaded. This means that GoogleBots crawling the site in the first wave will not detect the additional <H1>.
You can also use Google’s Mobile Friendly Test to identify if content has been injected via JavaScript. If you opt to use this method to test, you will need to compare both the test results and the page source code. As well as looking for differences in content, you will need to examine disparities for common attributes such as:
In this example, hreflang was removed by a JavaScript:

The fr-fr hreflang is showing in the source code even though JavaScript has been disabled.
However, the Mobile Friendly Test result highlights that the fr-fr hreflang is missing. In this instance, a JavaScript that was written to especially remove the hreflang on this site when they did a pre-launch of the French site was not removed after the launch as intended.

It is best practise to avoid injecting any: content, elements or attributes in the DOM that could negatively impact your SEO, using JavaScript. This is because Google will not render the JavaScript on the first wave of crawling, so these elements may not be indexed immediately.
Best practice tips:
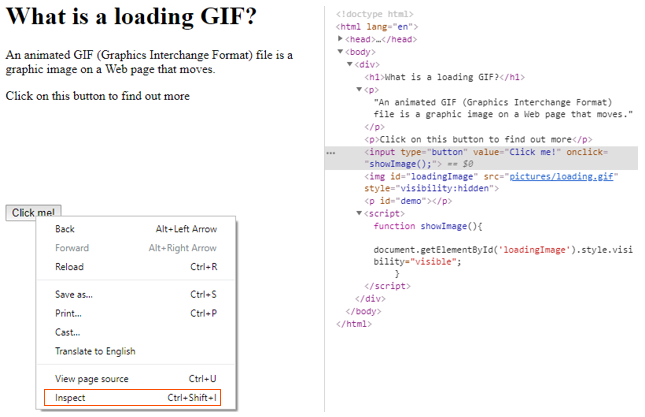
Search engines can only crawl and follow links on webpages which have been tagged with <a href=>. However, it is possible to create links to another webpage using JavaScript, via JavaScript’s ability to create ‘onclick events’ which execute a function when a button is clicked:
<button onclick=”myFunction()”>Click me</button>
When external links are built this way using JavaScript, they do not have the <a href=> which means that the links will not be crawled. For websites which are predominantly built using JavaScript links, robots are unable to crawl any pages linked internally.
The most efficient way of checking whether on-page functions are built using JavaScript or using the relevant tags is through the Developer Console in your browser. In Chrome, you can right click any part of a webpage and then go to “Inspect” and its code will then become highlighted in the console under the “Elements” tab. Any content, link, button, image, icon or any other functionality can be inspected like that.
In some instances, JavaScript dynamic functionalities may open a new page with a different URL, which can be particularly problematic. In the example below, internal links were generated via a JavaScript coupled with <svg> images:

After this method of linking was introduced, the website showed a dramatic loss of crawl followed by a huge loss of traffic.
The solution to this issue is to make sure that all internal links are generated with the < a href=> method, even when JavaScript is used to create dynamic functions on a page.
Note: The xlink:href method is now deprecated and it is recommended to use <a href=>.
JavaScript redirects are easy to implement and don’t require back end developers to set-up redirects from the server. As a result, they are widely used by web developers as a quick solution.
Since there are now JavaScript enabled GoogleBots, Google is able to understand JavaScript redirects (JS redirects) and will follow these types of redirects the same way they follow traditional 3XX redirects. However, this will only occur after the second wave of GoogleBots have visited the page, which means that redirects may take days or weeks to take effect – during this time, the original page has had time to be crawled and indexed by search engines.
Unfortunately, this issue is more difficult to detect – you will need a crawling tool which can render JavaScript. We use ScreamingFrog to troubleshoot JavaScript redirects; this can be enabled in the Spider Configuration settings.
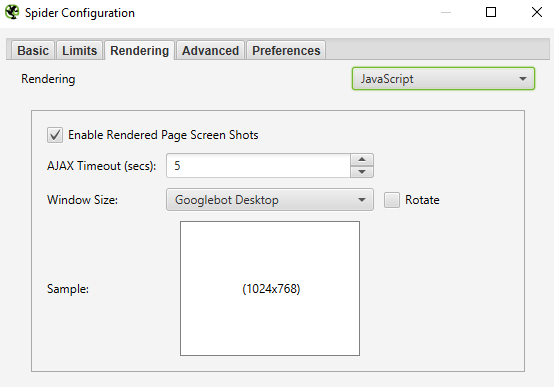
Once you have run the website crawl using a tool, you are able see the difference in site performance when JavaScript is either enabled or disabled.
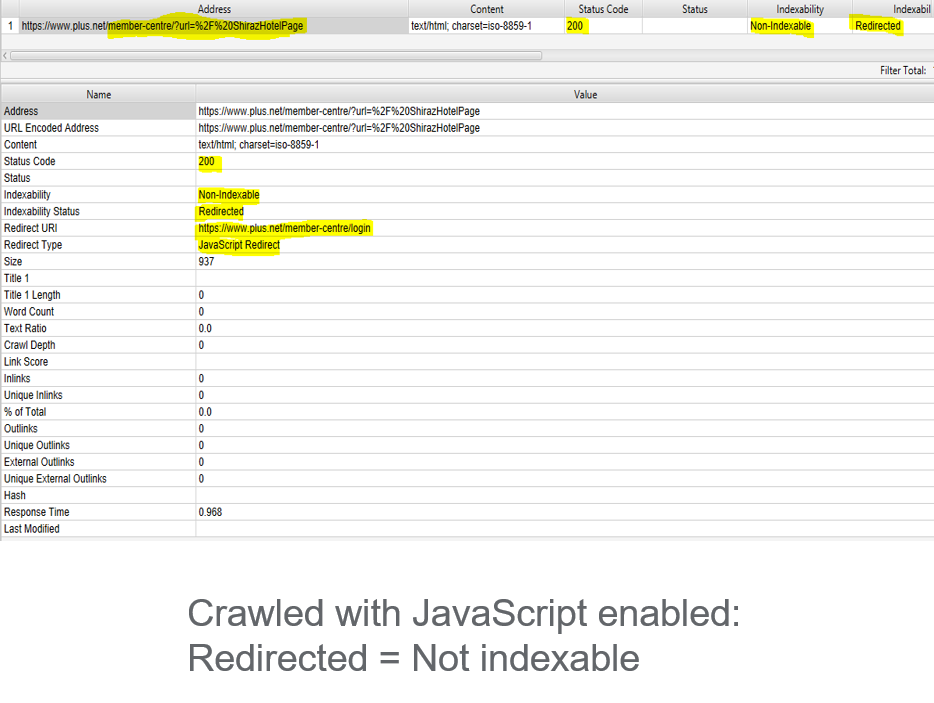
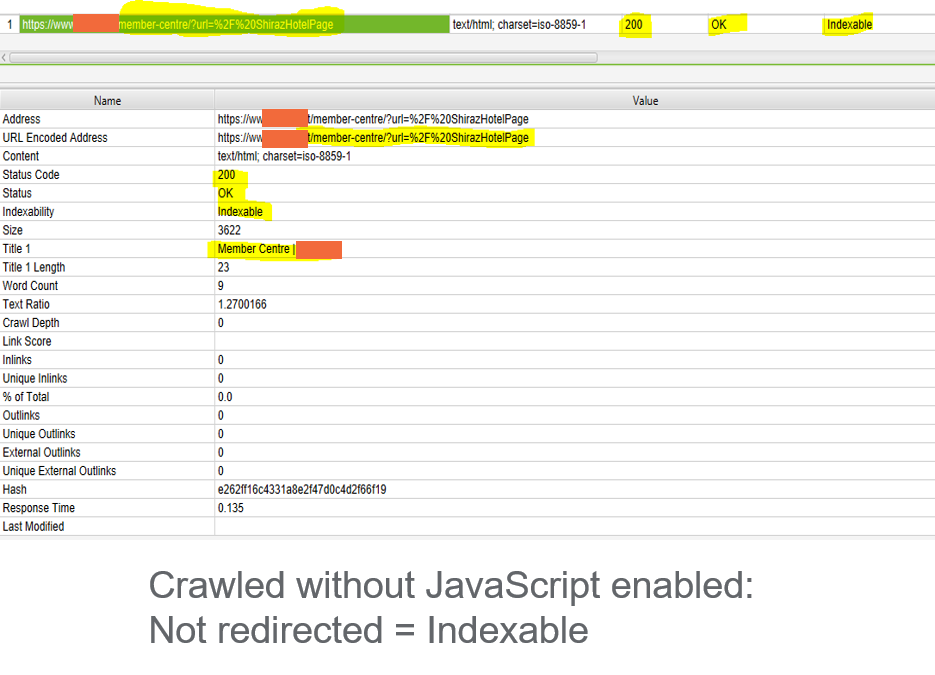
Unlike server-side redirects, JavaScript redirects can only be setup on individual pages and implementing redirect rules based on pattern and regex is almost impossible. This means there is usually minimal amounts of redirects to address; it usually happens because it has been combined with traditional server-side redirects, for example:
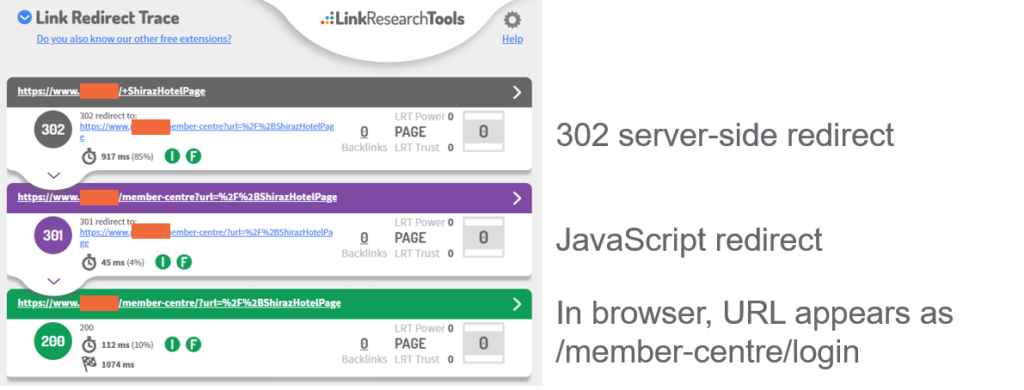
Using the Chrome extension Link Redirect Trace, we can see that a catch all 302 redirect was implemented on this website which sends users and robots to a new URL containing a parameter “?url=”, creating thousands of new URLS.
Although users will not see any difference, robots consider these parameter URLs as unique URLs and will class each as a separate page, creating thousands of duplications. While there is a JavaScript redirect in the parameter URLs setup to send users to a single clean URL, most robots are not able to see this last redirect.
The main exception is a JavaScript enabled GoogbleBot, but even here it is flagged as an issue as it uses up a large amount of crawl budget. The ‘Page with redirects’ report in Google Search Console shows the extent of such crawl budget waste for this client:
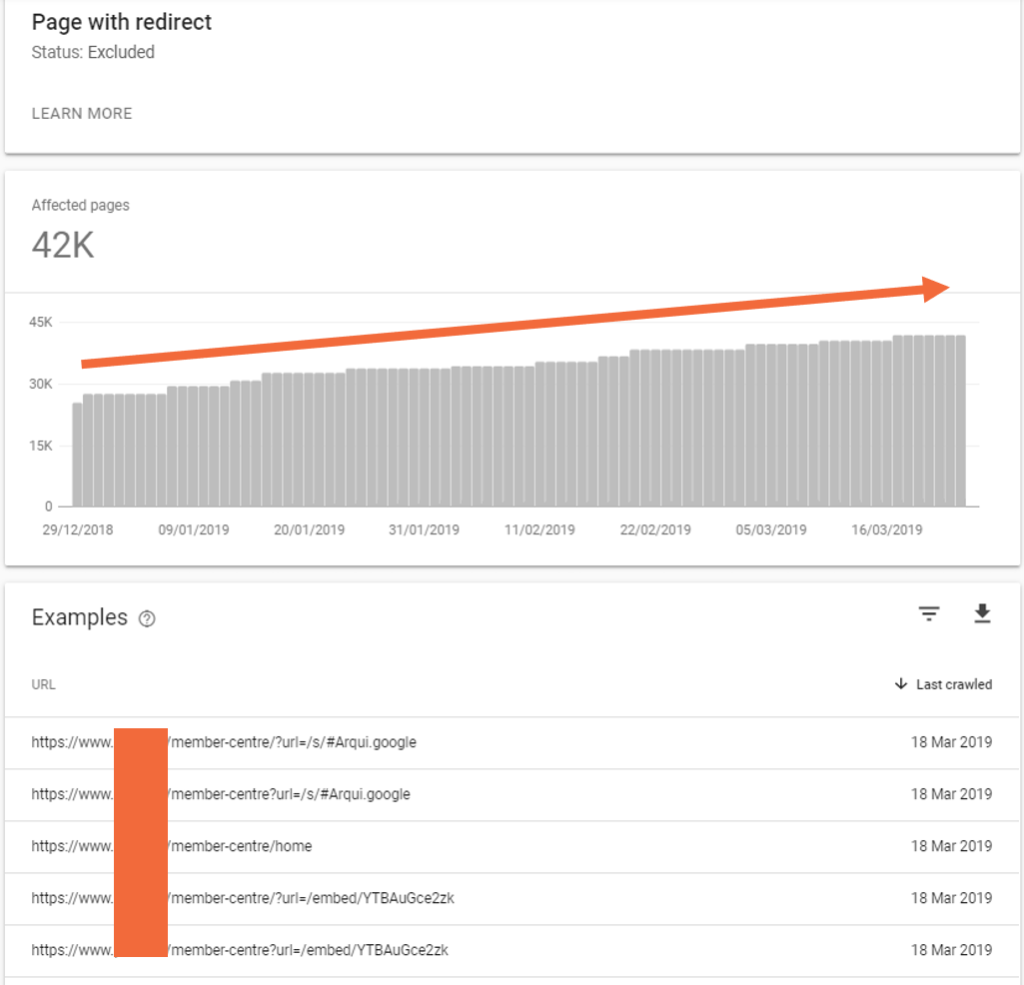
To fix the above issue we recommend the removal of the catch-all 302 redirect.
While JavaScript can provide an easy solution for web developers, it is crucial to ensure it is implemented in a search-friendly way. Our technical SEO team can audit your site and identify if JavaScript is impacting your organic visibility, and how to fix it.
This blog is part of our wider B2B Playbook that is designed to help B2B businesses with all aspects of their digital marketing from leveraging data, acquiring more traffic, creating assets that resonate and succeeding internationally.
In the traffic section. we take a look at your paid search and organic methods to grow your reach to get the right traffic to turn into more conversions.
![]() Insights
Insights

![]() Insights
Insights

![]() Insights
Insights