Google has been sending out waves of warnings via Search Console to webmasters who are blocking CSS and JavaScript on their websites with their robots.txt file. These warnings follow on from last October when Google announced that blocking CSS and JavaScript could result in ‘suboptimal’ rankings. This wasn’t the first time Google recommended against this practice though, Matt Cutts made a video about it back in 2012.
This is a brand new warning in Search Console though and is being referred to as [WNC-658001].
The warning states that there was an issue detected on your homepage that affects the way Google’s algorithms render and index your content – if Googlebot cannot access your Javascript and/or CSS files then this could result in “suboptimal rankings”.
To fix the issue, log into Search Console and navigate to ‘Fetch as Google’ under the ‘Crawl’ dropdown:
Then click the ‘Fetch and Render’ button:

Once complete, click the URL (or a slash in the case of the home page) to view the rendered page vs what users can see. Underneath these images will be a list of resources that Google was unable to get when rendering the page. It will specify the type of file, the reason it was unable to get the file and in cases of the file being blocked via robots.txt, a link to the robots.txt testing tool which will then highlight the offending line which is blocking that particular resource. If your site is running on WordPress, look out for the /wp-includes/ directory being blocked.
Once you have made the necessary changes to your robots.txt file, fetch and render again (making sure to test with “Mobile: smartphone” as well as Desktop) to ensure that Google can now get the resources it needs to render the page properly.
You can also view site wide blocked resources by navigating to the ‘Blocked Resources’ page under the ‘Google Index’ dropdown:
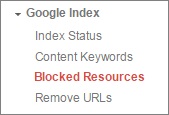
Please take note of these messages as we have in the past seen real improvements in visibility for our clients when allowing Google to crawl CSS and JS files. Just a couple of months ago we had a new client who needed some technical work doing on their site, unblocking JavaScript being one of our recommendations. The chart below shows when the changes were implemented and the resulting visibility increase.
Update
Yesterday on Stack Overflow Google’s Gary Illyes (user name ‘methode’) shared some tips on fixing the issue.
He said that the simplest form of allow rule would be:
User-Agent: Googlebot
Allow: .js
Allow: .css
This would allow any .js or .css file to be crawled as long as they don’t sit in a blocked directory. If they do sit in a blocked directory then an amendment should be made. The example Gary gives is:
User-Agent: Googlebot
Disallow: /deep/
Allow: /deep/*.js
Allow: /deep/*.css
This is disallowing the /deep/ file from being crawled but allowing any .js or .css file within that directory to be crawled.


