


![]() Insights
Insights
Analytics and Data Science
A crucial element of SEO is creating quality content which is highly relevant to search terms you want to rank for. Understanding content relevancy is not straightforward, however; gone are the days where we could trick a search engine into thinking content relates to a topic by stuffing pages and tags with as many keywords and synonyms as possible.
Google is continually improving its ability to understand human behavior and language. The search engine’s ability to translate user intent and match this to website content is better than ever, meaning we need to improve our ability to measure relevancy so we can create content which Google perceives as being more genuinely useful, and therefore more worthy of ranking.
Last year, Google published a paper on a sentence embedding model which they named Universal Sentence Encoder. They also published trained models on TensorFlow Hub so that developers and machine learning engineers can use these embedding models in their own tasks.
We have used this model to develop a Content Relevancy Tool which allows us to get an accurate measure of how relevant content is to a given keyword, topic or concept. The tool has been built into our custom software suite, SEOLab, however we decided to also make it publicly available so you can test how relevant your own site content is.
You can use our Content Relevancy Checker below. We talk about how it works, and what the different scores mean, further down in the blog.
The Universal Sentence Encoder is an example of a sentence embedding model – but what exactly does this mean?
In 2013, a team at Google published a paper describing a process of training models to learn how words could be represented in a vector space; representing words or phrases in a vector space in this way is what we mean by word or sentence embeddings.
Since the paper was published, the concept quickly became a very popular means to represent textual content for any downstream natural language machine learning task and has broken through previous boundaries of what was possible in the AI Natural Language discipline. It’s no coincidence that we have seen a huge explosion in the capabilities of AI assistants such as the Google Assistant and Alexa since the publication of this paper.
The term vector space has a specific mathematical definition but, for this blog, we can build up an understanding of a vector space as a multi-dimensional co-ordinate system that allows us to model the relatedness of words in different concept directions.
For example, consider this simplified case where we want to develop some measure of the similarity between the following five words:
If we were to restrict our notion of similarity to a very narrow conceptual context then we could start to do this task intuitively.
For example, if we were to consider the chemical composition of each of these substances, we might consider mercury to be very similar to gold and to lead because all three are metallic chemical elements. In contrast, steel (being a mix of other metallic elements) and diamond (being carbon – a non-metallic element) might be considered less similar.
In trying to represent a notion of similarity within the ‘chemical composition’ concept of these words we might draw them on a line which looks something like this:
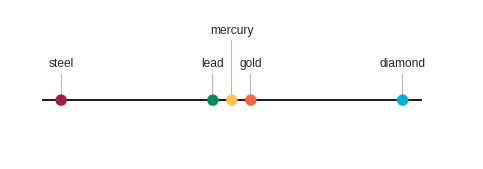
In this context, the three metallic elements are close together whereas the alloy is further away in one direction and the non-metallic element is further away in the opposite direction.
However, if we were to look at the elements under a different context, the representation completely changes. For example, if we are interested in the preciousness of the substances rather than the chemistry, diamond and gold are more similar (with diamond being considered even more precious than gold) but steel, mercury and lead are not really thought of as precious at all.
So, this time around we might draw a line like this:

We might also need a third, more general picture of how similar these words are – one which considers both the preciousness concept and the chemical composition concept. We can achieve this by looking at both concepts in two dimensions with preciousness on one axis and chemical composition on the other and visualizing the distance between them with a 2D plot:
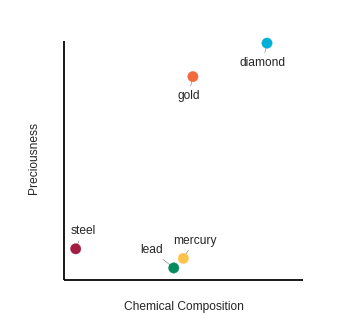
Even with two dimensions, we can still easily calculate the distance between these points using a simple formula – but is this an accurate representation of the general distance between these words?
While this is a better representation than either individual concept by itself, there are still other conceptual contexts these words could be considered within. For example, within the context of toxicity, lead and mercury are commonly known for their toxicity whereas the other elements are not, so we might have to add yet another dimension:

We could just about make a visualization plot with three dimensions, but it is much more difficult and as soon as we add any additional dimensions it becomes near impossible. The Universal Sentence Encoder, however, encodes text into a 512-dimension vector space, and as the mathematics that allow us to calculate a distance between these points still holds up for any arbitrary number of these contextual dimensions so we can still calculate distances in such high-dimensional spaces.
It is upon this premise that word embeddings represent a more general meaning of words. Machine-learning models can be trained on a massive corpus of text to represent a large vocabulary of words in a high dimensional space such that we have an accurate representation of the ‘distance’ between words in the vocabulary across a great many concepts.
Of course, we are stretching the definition a little to help our explanation; language and natural language understanding are far more nuanced than our illustrative example. ‘Axes’ in trained embedding spaces do not directly represent discernible concepts as they do our simple illustration above, and how distance is measured in these spaces are unlikely to be measured in the same way we have visualized; they are much more likely to be interested in the angle between the vectors than we are in measuring a scalar distance between points.
We can use real examples to highlight the depth of contextual knowledge these sentence embedding models have.
Take the now famous example, King – Man + Woman ≈ Queen. If we take the representation for the word ‘king’ in a word vector-space embedding, subtract the representation of the word ‘man’ and then add the representation for the word ‘woman’, we end up with a vector that is very close to the representation of the word ‘queen’.
In the example Vodka – Russia + Scotland ≈ Whiskey, we take away the representation for the word ‘Russia’ from the representation for the word ‘vodka’ and add in the representation for the word ‘Scotland’, ending up with a vector that closely represents ‘whiskey’.
These examples give valuable insight into the depth of knowledge embedded within these models; the first demonstrates a clear gender concept, while the second shows a clear ‘place of origin’ concept.
The Universal Sentence Encoder enables us to model a word, sentence or short passage of text in a vector space in such a way as to easily allow us to measure the distance (or relevance) to another word, phrase or passage of text.
We can use this principle to see how relevant content is to a search term. While it is easy enough to embed a keyword or search term, doing so for entire webpages poses a few problems; we first need to be able to extract the content from a given webpage, and then embed this content into the same vector space.
An additional issue is that a webpage’s content is typically built up of many small text passages, each with differing levels of importance.
In order to overcome these challenges, we need:
We will first consider points one and two together.
There are several factors that mean we are unable to extract the text passage by parsing the HTML from a page URL: webpages may be loaded asynchronously, rendered with JavaScript, responsive to screen size, or any number of things that mean that the HTML downloaded from the page URL is not the same version a user sees.
An easy way to render the page in the same way it appears to a user is to load the webpage and then copy and paste the text. However, this is time consuming to do at scale; we need to find a means to automate normal browser function. Solutions for this include phantomjs, Selenium and accessing Chrome in headless mode.
Technically, we can now parse the HTML of rendered pages using a script. However, this would not produce consistent and effective results across all webpages as we do not want to include all page content – for example, site navigation or legal disclaimers. We would need to use deterministic rules to ensure this content is excluded; the number of rules and possibilities needed to do this for webpages at scale is indefinite, and therefore not feasible.
In addition to needing rules to determine if a specific HTML section forms part of the main page content or not, we would also need a set of rules that identifies how important a text section is to the overall content of a webpage – does a section in small print at the bottom lend more weight than the title at the top? What about a section off to the side? How do you know where the HTML sections are rendered?
There are just too many ways one could structure HTML, CSS and JavaScript to realistically be able to contemplate this task using a deterministic approach. Even if we were able to create rules which worked, web development changes so quickly that they would soon be obsolete: all it takes is a new CMS to be release or a new web design paradigm to emerge, and the rules no longer apply.
Taking a deterministic approach to content extraction is therefore not possible in this instance. However, humans are able to do this intuitively very easily; most people are able to identify which text is part of the main page content without having to read the webpage content, using visual cues such as the page layout.
Google’s own search guidance adopts a similar method in how they approach analyzing a webpage:
Google takes into account your non-textual content and overall visual layout to decide where you appear in Search results. The visual aspects of your site helps us fully digest or understand your web pages.
By using visual cues, Google is better able to understand the content we post on site in the same way a human does, and therefore deliver content which humans find useful and relevant (rather than content which best satisfies a given model of relevance). By building a solution which emulates this approach, we would be able to create an evergreen tool which stands the test of time. We therefore decided to approach the task as a Machine Learning vision problem.

We gathered a large set of diverse pages from SERPLab’s historic searches and set about building a dataset we could use to train a neural network how to extract content. Instead of taking the HTML/CSS code the browser rendered, we looked directly at an image of the page. We then used the Google Vision API to recognize all the text-blocks each page contained:
We asked all of the Search Laboratory team to look over the page images and classify each of these text blocks as to whether they believed it formed part of the main content of the webpage. This gave us a huge labelled dataset of text blocks and the corresponding pages images, which we used to train a TensorFlow deep learning model to predict the likelihood of a given text-block forming part of the main page content.
We trained the model to use various features about the text block (such as its size, its location on the page, text-size, text-density, etc) as well as the page image itself (e.g. the visual layout and features that both humans and Google look at). As a result, we now have a reliable model that predicts the likelihood of a given block of text being considered part of the page’s content.
We then had to aggregate the results for each text-block of a page into a single score taking into account the weightings for the relative importance of each content block.
There are two different ways we could do this:
While it seems like these options both measure a similar thing, this is not the case; the first measures the distance from the ‘average content’ to a given search term, whereas the second measures the average distance to each content element.
For example: imagine we have extracted six text blocks from a webpage which, when embedded into our vector space, are in the positions below relative to the search term embedding:
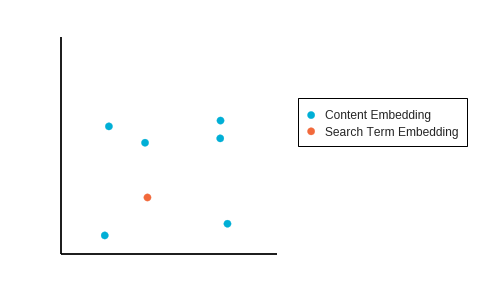
Using the first method we first take the average position of all the content embeddings then measure this against the search term embedding:
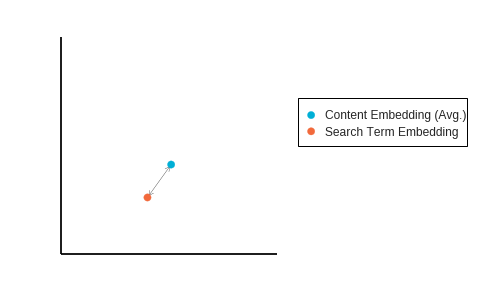
With the second method we calculate the distance to each content block from the search term before taking the average. We then average out all these different lengths, which gives a different distance result – in this example, the average distance of length is much larger in the second method than the first:
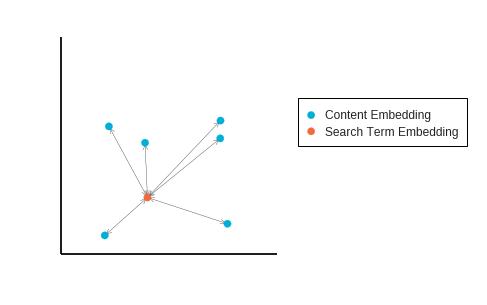
The first method tries to aggregate the whole page content into a single point, regardless of how diverse the individual content blocks are from one another while the second distance measure penalizes content that is diverse and not as focused on the search term – even if the aggregation of this content is very close to the search term. Each method gives a different distance result – so which do we use?
The first method is closest to what we set out to measure – the overall content relevance. The second method looks at how focused the content is, which is a useful bonus measure. We therefore decided that the Content Relevancy Tool should measure both, using the first method to measure overall relevance and the second to measure the content focus. By using normalization to convert the distances into a percentage score (where 100% represents zero distance and 0% represents an infinitely large distance), we can measure both the relevance distance and focus distance for a webpage’s content.
Having both scores means we can assess the usefulness of the content on a case by case basis, taking the topic and search terms into consideration. While it would make sense that we want both scores to be as high as possible, this may not necessarily be true for the focus score; how closely to the keyword the content stays while still being relevant to the search can depend entirely on the user’s search intentions. For example, a user searching for ‘malt whisky’ may be looking for the history of whisky and the distillery process, in which instance the content they want to see is only loosely focused.
There is no shortage of content relevance measuring tools available on the web. However, we have yet to find one that takes visuals cues into account and therefore best represents how Google measures content relevancy. Our tool is available to use for free, so you can measure your web content’s relevancy independently and with zero obligations.
The Content Relevancy Tool is one of almost 20 custom tools we have developed internally to help manage our clients’ accounts more efficiently and effectively. Get in touch to find out more about our proprietary tools and how they can help you grow online.
This blog is part of our wider B2B Playbook that is designed to help B2B businesses with all aspects of their digital marketing from leveraging data, acquiring more traffic, creating assets that resonate and succeeding internationally.
In assets, it’s all about getting the right message to the right audience at the right time. Here we review how to use personalized content to provide a better user experience for your customer so you can get more conversions.
Get the latest insights from our team delivered straight to your inboxSubscribe to our newsletter
![]() Insights
Insights

![]() Insights
Insights

![]() Insights
Insights