
![]() Insights
Insights
Head of Analytics
Analytics and Data Science
On the 25th October 2019, Google announced what it said was “…a significant improvement to how we understand queries, representing the biggest leap forward in the past five years, and one of the biggest leaps forward in the history of Search.”
That improvement is BERT, the natural language processing system which has become part of Google’s search algorithm. BERT stands for Bidirectional Encoder Representations from Transformers – which for anyone who’s not a machine learning expert, may sound like somebody has picked four words at random from the dictionary. We’ll explore the meaning behind these words later in this blog.
The algorithm has yet to be rolled out worldwide but currently, it can be seen in the US for regular search results, and for featured snippets in other languages where they are available.
To understand what BERT is and how it works, it’s helpful to explore what each element of the acronym means.
An encoder is part of a neural network that takes an input (in this case the search query) and then generates an output that is simpler than the original input but contains an encoded representation of the input.
In Natural Language Processing, we train the encoder to be able to take a block of text, word or word fragment and output a vector (array) of numbers. This vector encodes information about the encoded text and is its representation.
We can often do this stage in an unsupervised way and reuse the learned representations (or embeddings) in many subsequent tasks. For example, we might first train a model to predict the next word over a vast set of text. We can then reuse the subsequent results to train with a much smaller specific labelled dataset to retrain on a specific task – such as sentiment analysis or question answering. The initial training, while slow and data-intensive, can be carried out without a labelled data set and only needs to be done once. Wikipedia is commonly used as a source to train these models in the first instance.
Until recently, the state-of-the-art natural language deep learning models passed these representations into a Recurrent Neural Network augmented with something called an attention mechanism. However, in December 2017 a team at Google discovered a means to dispense with the Recurrent Neural Network entirely. They were able to obtain slightly better results using only the attention mechanism itself stacked into a new architecture called a transformer. They published their breakthrough findings in a paper called Attention is All You Need.
The new architecture was an important breakthrough not so much because of the slightly better performance but more because Recurrent Neural Network training had been difficult to parallelise fully. Transformers, on the other hand, were quicker to train and parallelised much more easily.
The bidirectional part means that the algorithm reads the entire sequence of words at once and can see to both the left and right of the word it’s trying to understand the context of.
Whilst bidirectional language models have been around for a while (bidirectional neural networks are commonplace), BERT moves this bidirectional learning into the unsupervised stage and has it ‘baked in’ to all the layers of the pre-trained neural network. The BERT team refers to this as deeply bidirectional rather than shallowly bidirectional.
In short, the breakthrough BERT provides is to leverage the new transformer architecture to push a much deeper representation of language into the unsupervised reusable pre–training phase. This means that Google (and anyone else) can take a BERT model pre-trained on vast text datasets and retrain it on their own tasks. In doing so we would generally expect to need less specialist labelled data and expect better results – which makes it no surprise that Google would want to use as part of their search algorithm.
While the official announcement was made on the 25th October 2019, this is not the first time Google has openly talked about BERT. More than a year earlier, it released a paper about BERT which was updated in May 2019. In November 2018, Google even open sourced BERT which means anyone can train their own question answering system.
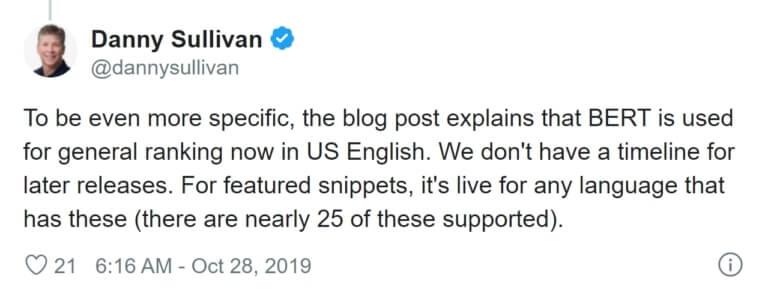
One of the datasets which Google benchmarked BERT against is the Stanford Question Answering Dataset (SQuAD) which, in its own words, “…tests the ability of a system to not only answer reading comprehension questions, but also abstain when presented with a question that cannot be answered based on the provided paragraph.” Part of this testing involved a human performance score which BERT beat – making it the only system to do so. It’s no surprise that we’re now seeing it helping to improve Google’s search results.
F1 indicates the measure of accuracy
Historically, Google’s algorithm updates have been focused on fighting spam and poor-quality webpages, but that’s not what BERT does. Fundamentally, BERT is here to help Google understand more about the context of a search query to return more relevant results. This means that there is no need to optimise your content or website for this algorithm – it still looks at the same factors, but now has a better understanding of which results to show.
BERT in no way assesses the quality of your website or webpages, it’s there to help Google better understand the context of search queries.
Google has provided some examples of how SERP results have changed following BERT’s input. These really highlight the power of the model and how it will positively impact all users of Google search.
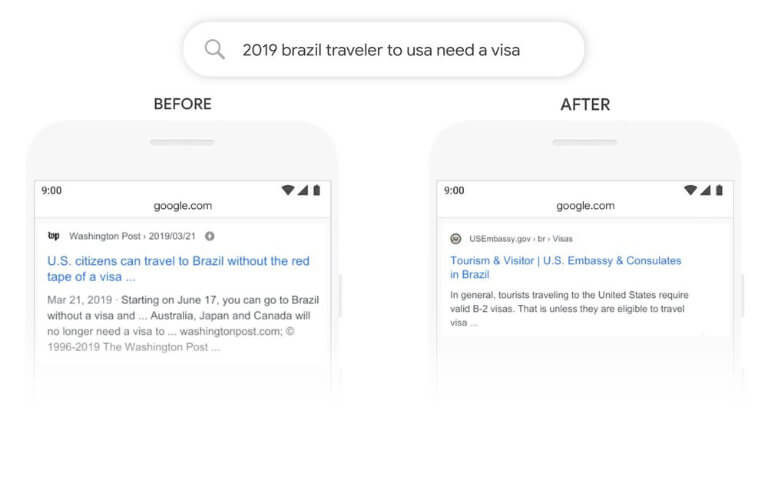 In this example, the pre-BERT result was returned without enough emphasis being placed on the word ‘to’ and Google wasn’t able to properly understand its relationship to other words in the query.
In this example, the pre-BERT result was returned without enough emphasis being placed on the word ‘to’ and Google wasn’t able to properly understand its relationship to other words in the query.
Post-BERT, Google is able to recognise that ‘to’ is actually a crucial part of the phrase in properly understanding the query and a much more relevant result is being returned. Now the result is aimed at Brazilian travellers visiting the USA and not the other way around as it was before.
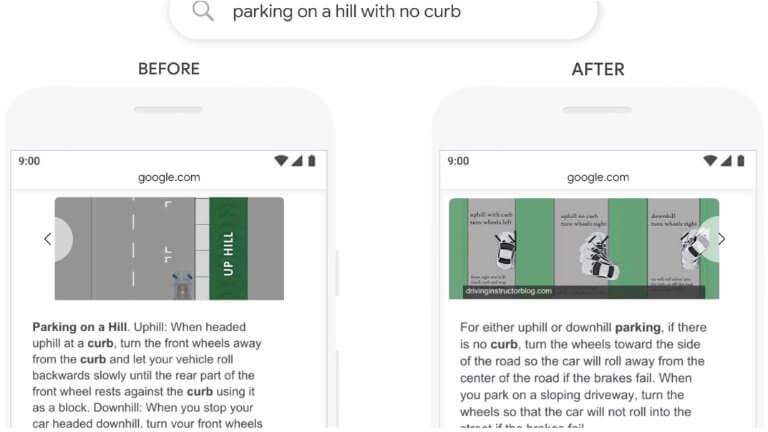
This example shows a featured snippet as opposed to a regular search result (remember that BERT is being used for both). Pre-BERT, Google said that it simply ignored the word ‘no’ when reading and interpreting this query. However, ‘no’ makes this a completely different question and therefore requires a different result to be returned in order to properly answer it. By BERT understanding the importance of the word ‘no’, Google is able to return a much more useful answer to the users’ question.
If your organic search traffic from Google has decreased following the roll-out of BERT, it’s likely that the traffic wasn’t as relevant as it should have been anyway – as the above examples highlight. It’s most likely that you will have lost traffic on very specific long-tail keywords, rather than commercial terms or searches with high purchase intent.
If you want to understand where you have lost traffic, find out which keywords which are no longer driving traffic to your site and look at what’s now ranking for those queries – is it on the same topic but different intent?
To regain traffic, you will need to look at answering these queries in a more relevant way. Your options are to rework the content which was ranking for that query to match the new intent or create a new piece of content to target it. The latter option is probably the best one as changing the original content and the intent behind it can mean the loss of other more relevant keywords which are still driving traffic to it having retained their ranking positions.
If you have seen a net gain in organic traffic following the implementation of BERT, it is likely that you have relevant content which was previously underperforming as Google did not understand the context of the content in relation to relevant search queries.
The introduction of BERT is a positive update and it should help users to find more relevant information in the SERPs. It will also help the Google Assistant deliver much more relevant results when the query is made by a user’s voice. Voice queries are typically more conversational in nature and the more Google is able to understand the nuances involved when querying its index in a conversational tone, the better the returned results will be.
SEO is evolving extremely quickly. User journeys are more fragmented, generative AI is now part of search engines and Google’s core updates are still making changes, all of which are leading reasons for changes in SEO.
The Future of SEO report, co-authored by James Bentham and Amy Banks, addresses these issues and contains detailed insights on how marketers can realign SEO strategy to achieve success. By doing so, brands can develop future-proofed solutions.
![]() Insights
Insights

![]() Insights
Insights

![]() Insights
Insights