The use of the rel=”nofollow” tag has been hotly debated online and has shown a number of contrasting opinions being put forward by leading SEO experts. Google’s official guidelines around its usage can be found here, but here’s the main point:

In the past, the nofollow tag has primarily been promoted by Google as a way to prevent PageRank or other link authority being passed through links and typically was recommended for when you didn’t necessarily trust the destination of the link, or that a link was paid-for. However, many sites utilise the rel=”nofollow” tag as a way to moderate crawl budget internally and ensure that top performing landing pages were crawled with the greatest priority (for example when using faceted navigation). This seems sensible, however this recent post by Rand Fishkin at Moz suggests that this practice isn’t correct and won’t actually prevent search engines from physically crawling the link:


Ok now I’m confused… There’s Google telling us one thing, but also one of the industry’s leading experts telling us another. So, in order to get to the bottom on this debate, we decided to test it for ourselves! Read on to find out what our tests revealed….
Testing the theory
Here at Search Laboratory we have our own portfolio of testing domains, operating in highly-controlled scenarios where we can run tests on different aspects of SEO theory in order to submit only the best, proven recommendations to our clients. Here, we attempted to answer the question – Does Google crawl nofollow links?
Test requirements
- 2 x unused testing domains
- Set of raw access (server log) files for each domain
Test process
- Ensure both sites are blocking all search engine crawlers in the robots.txt file before launching the test. We don’t want any bots crawling the sites and invalidating our study before we’ve even started!
- Set up three live pages on each site – a homepage, a second page (in this case we called it /page-b/), and a third page (/page-c/)
- Set up one link from the homepage to /page-b/ and add the rel=”nofollow” tag
- Set up one link from the homepage to /page-c/ without the rel=”nofollow” tag (we did this to make sure that Google was actually crawling the sites and not just ignoring them completely!)
- Unblock the sites to all search engine crawlers in the robots.txt file and use the Fetch As Google tool in Google Search Console. We selected ‘Crawl only this URL’ to make sure that Google would find the nofollow link naturally and not by us giving it a helping hand:
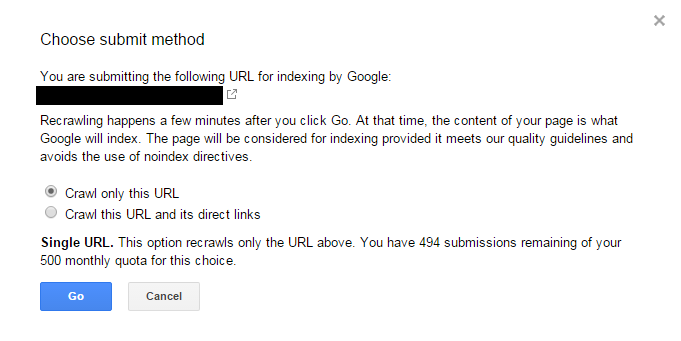
- Monitor Googlebots activity on the sites using raw access log files.
Test results
We launched this test over one month ago (20th July 2015) and have access to a lot of raw access activity by Googlebot. In July we saw the following activity on our two sites:
Site 1:
|
URL |
Crawl instances |
| robots.txt | 57 |
| Homepage | 20 |
| /page-b/ | 0 |
| /page-c/ | 4 |
Site 2:
| URL | Crawl instances |
| robots.txt | 40 |
| Homepage | 10 |
| /page-b/ | 0 |
| /page-c/ | 3 |
We were still skeptical that Google might simply not have detected the link to /page-b/ so we went back into Search Console to give it a further nudge in the right direction:
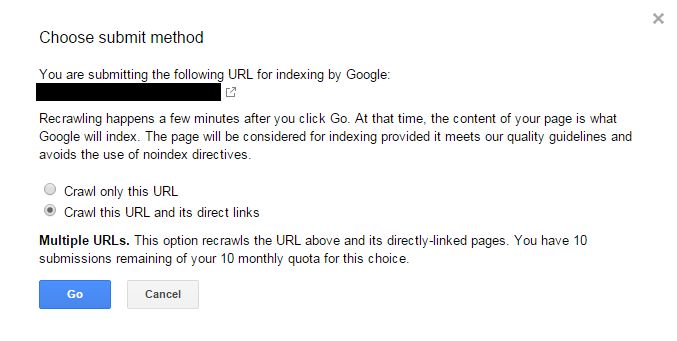
And the most recent data (taken 24th August 2015) shows the following crawl activity by Googlebot:
Site 1:
|
URL |
Crawl instances |
| robots.txt | 113 |
| Homepage | 69 |
| /page-b/ | 0 |
| /page-c/ | 8 |
Site 2:
| URL | Crawl instances |
| robots.txt | 75 |
| Homepage | 39 |
| /page-b/ | 0 |
| /page-c/ | 4 |
Still absolutely no crawl activity by Google on our nofollow link! Despite Google finding our site 113 times and 75 times respectively, crawling our homepage 69 times and 39 times, and even following our link to /page-c/ a handful of times on each site, we saw zero hits on /page-b/, which was only accessible through that nofollow link on our homepage.
Test conclusion
Despite this test being run on a small scale (only two test websites and two linked pages per site), we can still draw a solid conclusion from this data and infer that Google was honouring the rel=”nofollow” tag on our link and not even crawling the linked page. Therefore, it is our opinion, based on this study, that Google does not crawl nofollow links, and that these markups can be used for controlling crawl budget and conserving indexation.


