We discussed the use of iframes in this blog post two years ago, and our conclusion was that you should avoid them.
We revisited the issue recently, and undertook some tests to see if and how we could make iframes SEO-friendly.
The problem with iframes
Pages that have iframe tags display multiple URLs for one single page. You can even have an iframe page in another iframed page. Here is an example:
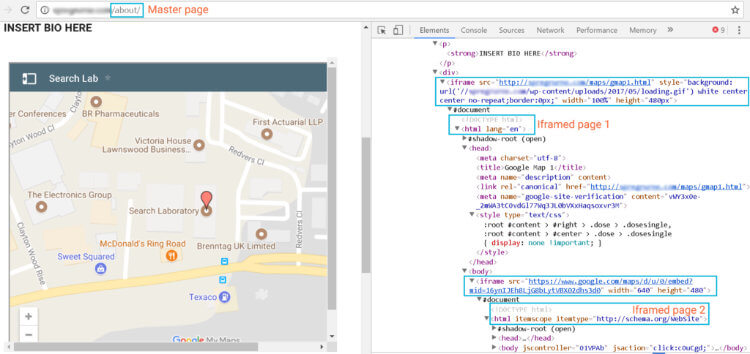
The html tag indicates the beginning of the code on a page and a conventional page should only have one. In theory, this means that the master page content containing all the iframe tags should be crawled including all associated iframed content. Therefore, link equity can be passed from a master page to an iframed page or vice versa.
In reality, however, there is still a risk that it will confuse search engine robots and result in the page content not being indexed as intended.
Google admit that whilst they try to associate framed content with the page containing the frames, they can’t guarantee that they always will.
In July 2017 John Mueller, Webmaster Trends Analyst at Google, further explained that it is not possible to control the crawl and indexation of iframed content. He said:
“In particular if a page is embedded within an iframe, within a bigger other page, then it’s possible that we will index that embedding page as well.”
There is also a concern that you are not in control of which content is crawled, and this could penalise your site in the long run.
We found that this lack of clarity was not ideal for our clients, many of whom use iframes. So we thought we would apply our standard scientific approach to the issue, and ran some tests in our Labs to see if we could find a solution that definitely works.
Test – can you control the crawl on an iframe?
In all the tests, the following terms are used:
- Master page: a page containing an iframe tag
- Iframed page or content: a page or content created that is placed on the master page as an iframe tag.
We identified four different techniques to test (‘no follow’ not being supported for the iframe tag):
- Canonical tags
- robots.txt
- meta robots noindex, nofollow
- Using an on-demand iframe.
Test one – using canonical tags
This is the method suggested by John Mueller from Google in the above-mentioned Hangout: using a rel canonical on the page, pointing to the actual content version that you want to index.
This is the step by step process for the test:
Step one
On domain one, we created a raw HTML page with a <title>, a <H1>, some <body> content and an image. We also added a self-referencing canonical. This is our iframed page:
[html]
<!doctype html>
<html lang=”en”>
<head>
<meta charset=”utf-8″>
<title>Loading GIF | Example of an animated GIF (Graphics Interchange Format)</title>
<meta name=”description” content=””>
<link rel=”canonical” href=”http://[domain one].com/gif/loading-gif.html”/>
</head>
<body>
<div>
<h1>What is a loading GIF?</h1>
<p>An animated GIF (Graphics Interchange Format) file is a graphic image on a web page that moves.</p>
<p>Below is a picture of a loading GIF.</p>
<img src=”http://[domain one]/wp-content/uploads/2017/05/loading.gif”>
</div>
</body>
[/html]
Step two
On domain two, we created a raw HTML with nothing on it except an iframe tag and a canonical pointing at the page on domain one. This is our master page:
[html]
<!doctype html>
<html lang=”en”>
<head>
<meta charset=”utf-8″>
<title></title>
<meta name=”description” content=””>
<link rel=”canonical” href=”http://[domain one].com/gif/loading-gif.html” />
</head>
<body>
<div>
<iframe src=”http://[domain one]/gif/loading-gif.html”
height=”500″ width=”750″ style=”border:0px;”></iframe>
</div>
</body>
</html>
[/html]
Results
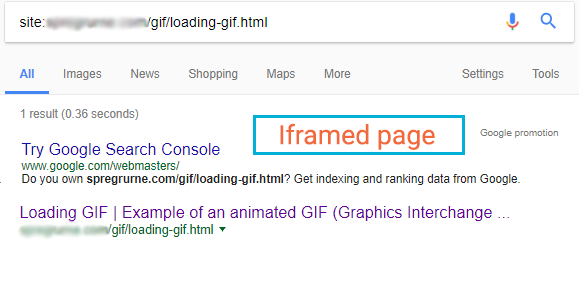
With the setup above, in theory, our master page shouldn’t get indexed. Only the iframed page should be indexed because of the canonical tag.
Day one
The results in the SERP were very surprising, as both our master page and iframed page were indexed.
Master page
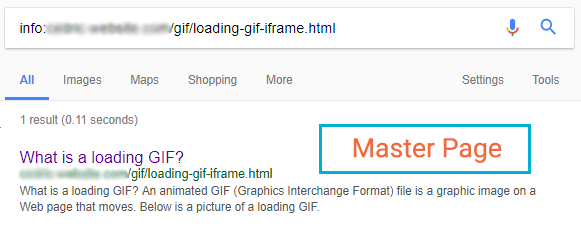
The title and meta description are included in this SERP. They are from the iframed page and the title is the <H1> whilst the meta description comes from the <body> content.
Iframed page
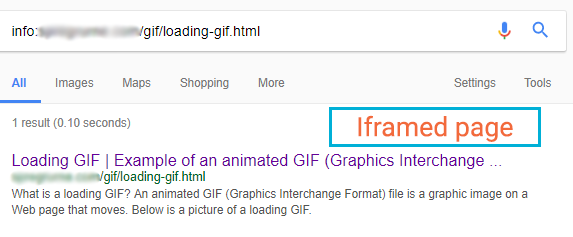
In this SERP, the title tag is honoured. There was no meta description set for this page, and again we can see that Google is using the body content to create it.
Day two
When we went back to the same pages the next day, the results were very different.
Master page
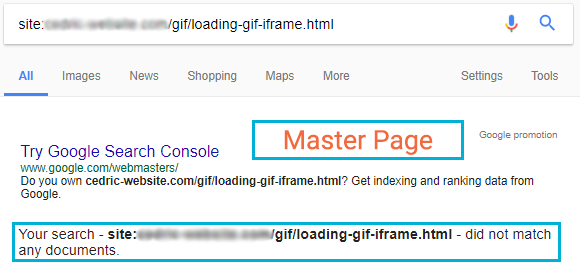
The page is not indexed anymore, the canonical has been honoured.
Iframed page
The page is still indexed. The title remains, but there is no meta description left. This is not surprising as it wasn’t specified in the first place.
Conclusion
John Mueller’s recommendation works. However, you need to have access to the other domain to add a cross domain canonical. As the first results were showing before the canonical was honoured, there was some cross-domain duplication. Without canonical tags, it would have a negative effect in the long run for both pieces of content.
The next part of the experiment will now test methods to block crawls on iframed content where you don’t have control of the other site. We have used Google Maps embedded as an iframe for these tests.
Test two – using robots.txt
The robots exclusion protocol is a good way of controlling pages and directories from being crawled by bots.
However, excluding the parent page from the crawl will have the adverse effect of deindexing it completely. So we created a second page containing only the iframe content and then blocked that page from being crawled.
Step one
We created a raw HTML page with a Google Map embedded as an iframe. The page needed to live in a subdirectory: http://[domain one]/maps/gmap1.html. This is our iframed page.
Step two
We blocked the Google Map <iframe> content by using robots.txt command:
[html]
User-agent: *
Disallow: /maps/
[/html]
Step three
We added the page as an iframe on http://[domain one]/contact/. This is our master page:
[html]<iframe src=”http://[domain one]/maps/gmap1.html” width=”640″ height=”480″></iframe>[/html]
To verify how the parent page was crawled by Google we did a fetch and render on http://[domain one]/contact/.
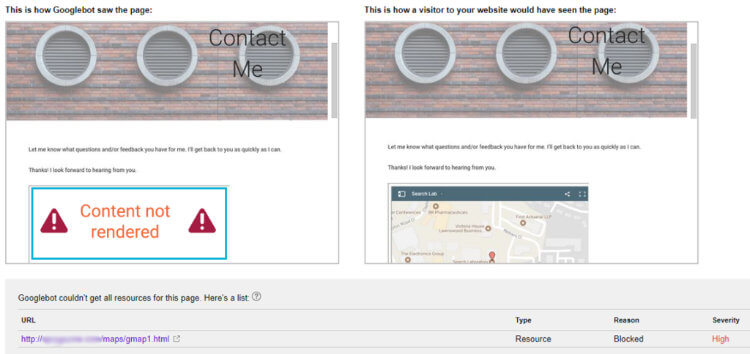
Our iframed page containing the Google Map was blocked with a Severity rating of “High”, although it was rendering for users.
Conclusion
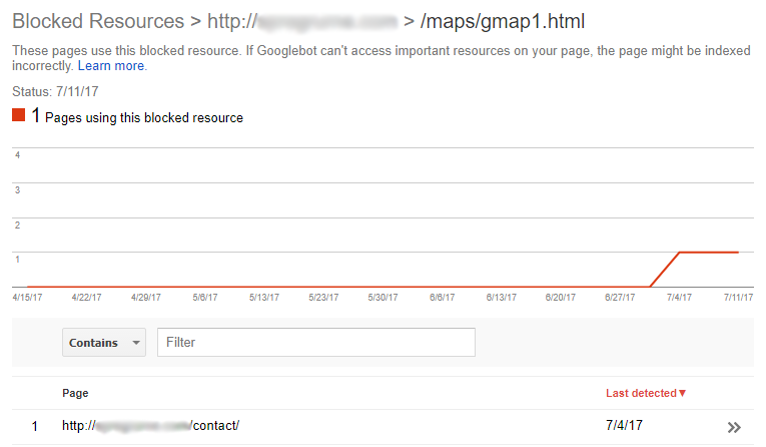
This approach will have a negative effect on your master page indexation chances. As mentioned in the blocked resources report in Google Search Console:
“If Googlebot can’t access important resources on your page, the page might be indexed incorrectly.”
Test three – Using meta robots noindex, nofollow
Meta robots are tags which can be included within the <head> of the page.
- To prevent robots from indexing the page, attribute “noindex”
- To prevent robots crawling the links on the page, attribute “nofollow”
Again, using this on our parent page would have some negative effect, so we need to use the same method as in test two i.e. we created a second page containing only the iframe content and then blocked that page from being crawled.
Step one
We created a raw HTML page with a Google Map embedded as an <iframe>: http://[domain one]/maps2/gmap2-noindex-nofollow.html.
This is our iframed page.
Note: this page sits in a separate directory /maps2/ because /maps/ is currently blocked from crawling (see test two)
Step two
We blocked the Google Map iframe content by inserting the meta robots tags on the iframed page:
[html]<html lang=”en”>
<head>
<meta charset=”utf-8″>
<title>Google Map 2 – noindex,nofollow</title>
<meta name=”description” content=””>
<meta name=”robots” content=”noindex,nofollow”>
<link rel=”canonical” href=”http://[domain one]/maps/gmap2.html” />
</head>
<body>
<iframe src=”https://www.google.com/maps/d/u/0/embed?mid=16ynIJEh8LjG8bLytVBX02dhs3d0″
width=”640″ height=”480″></iframe>
</body>
</html>[/html]
Step three
We added the page as an iframe on http://[domain one]/what-do-i-do/. This is our master page.
[html]<iframe src=”http://[domain one]/maps2/gmap2-noindex-nofollow.html” width=”640″ height=”480″></iframe>[/html]
Result
To verify how the master page was crawled by Google we did a fetch and render on this page: http://[domain one]/what-do-i-do/
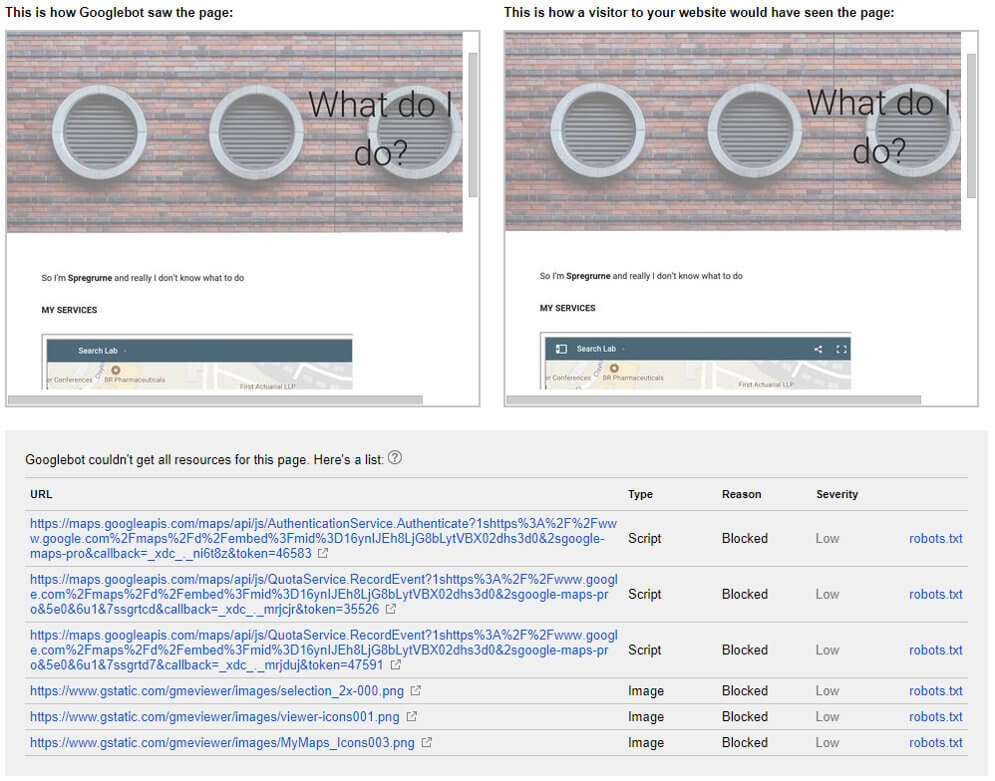
Conclusion
Once again, there isn’t a full, clean render and <script> is blocked. When looking closely, these scripts belong to the Google Map iframed content and not our test site.
So, despite the commands on the page, Google did follow the links on the iframe.
In this case, this method is like using rel=nofollow and therefore shouldn’t be used.
Test four – using an on-demand iframe
For this test, we are using an <iframe> code generator developed by codegena.com. The method used is also very similar to test two – using a robots.txt.
Step one
We created a raw HTML page with a Google Map embedded as an <iframe>. The page needed to live in a subdirectory: http://[domain one]/maps/gmap1.html. This is our iframed page.
Step two
We blocked the Google Map iframe content by using robots.txt command:
User-agent: *
Disallow: /maps/
Step three
We used the code generator and added the code in the body section on http://[domain one]/contact/. This is our master page:
[html]<div class=”codegena_iframe” data-src=”http://[domain one]/maps/gmap1.html”
style=”height:480px;width:640px;”
data-responsive=”true”
data-img=”http://[domain one]/wp-content/uploads/2017/05/google-map.jpg”
data-css=”background:url(‘//[domain one]/wp-content/uploads/2017/05/loading.gif’) white center center no-repeat;border:0px;”
data-name=”SL test”></div>
<script src=”https://rawgit.com/shaneapen/Codegena/master/async-iframe.js”></script>[/html]
This code doesn’t contain any <iframe> tag but rather some images, CSS styling and a script. All of this creates the “on-demand” iframe. The iframe is not loaded when the page loads, it’s only once a user clicks or taps on it that it starts loading as shown below.

Result
To verify how the master page was crawled by Google, we did a fetch and render on http://[domain one]/about/
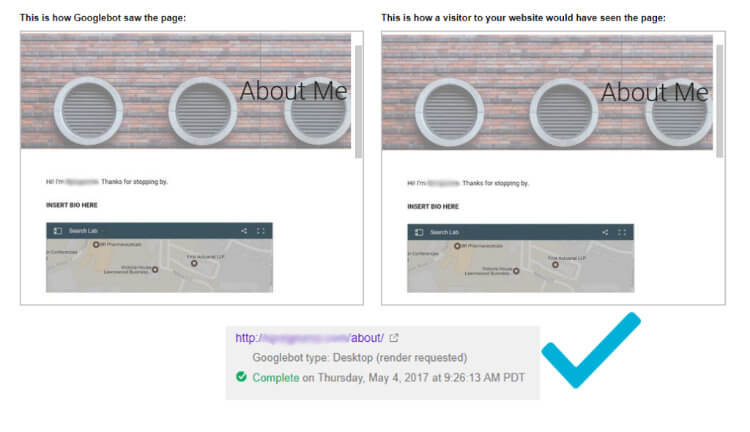
Conclusion
This time the render successfully completed. Page loading speed also improved, as shown on these speed test results from webpagetest.org:
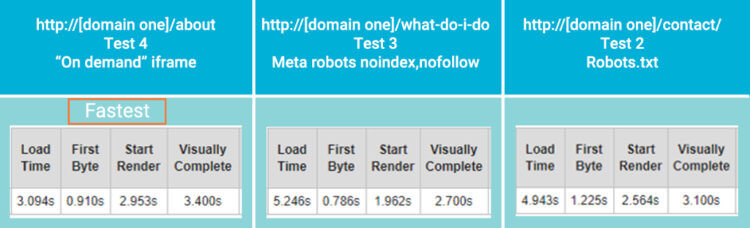
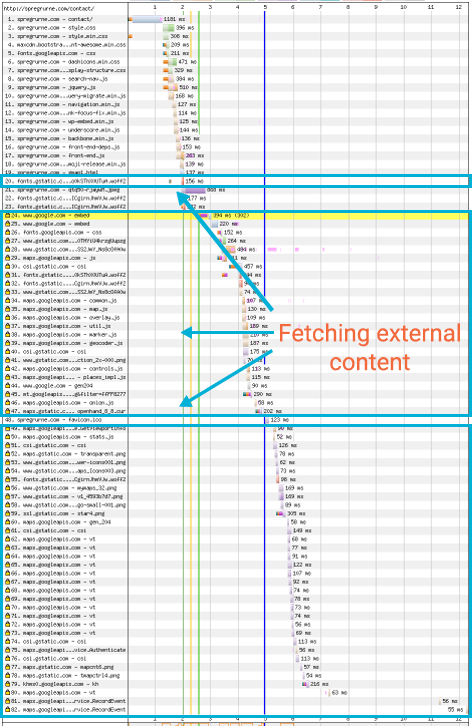
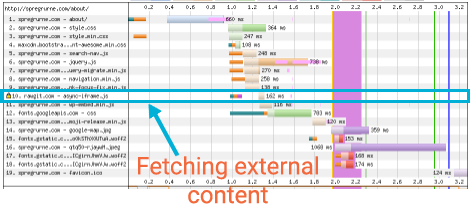
On all the speed tests we ran, the on-demand iframe method was always the fastest. This can be easily explained because there is less content being fetched from an external site, as is clear in the waterfalls for the pages:
- Page with a Google Map iframed:
- Page with a Google Map on-demand iframe:
Key takeaways
Our tests prove that there are different methods we can use to control how iframes are crawled by search engines, but only two of them work for SEO.
The table below summarises our results:
Method |
Success |
Comment |
|---|---|---|
| Canonical | Yes | However, it will only work if you own – or have access to – both master and iframed pages. |
| Robots.txt | No | Blocking resources will be reported, and Google will not give as much priority to your page as it should do. |
|
Meta robots |
No | In principal, it is the same as using the nofollow tag attribute and will not work. |
|
On-demand iframe |
Yes | This was by far the best method. The iframe content is delivered after the page has been crawled thanks to a script. |


